
로그 스태시란?
로그 스태시는 지어진 이름 처럼 과거에는 어플리케이션들에서 발생하는 로그들을 엘라스틱서치에 전달하는 역활만을 해왔다. 이는 가장 많이 활용해왔던 수단 중 하나였지만 점점 발점해오면서 데이터 전달하고 필터링 하는 역활도 할 수 있게 되었고 나중에는 인기 있는 데이터 파이프 라인 툴 중 하나로 자리잡게 되었다.
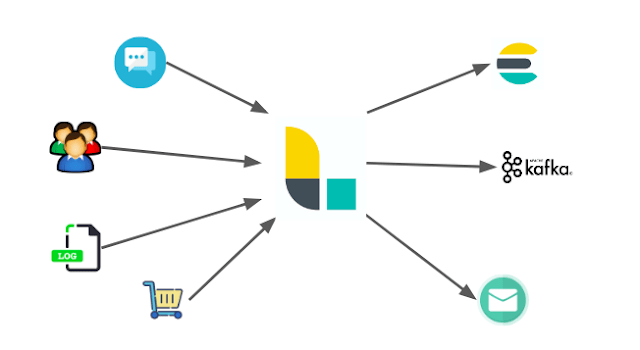
로그스태시는 다양한 이벤트들을 전달받아 핸들링할 수 있다. 이러한 이점은 다양한 형태의 데이터 처리 할 수 있다는 의미이기도 하다. 예를 들어 로그 파일, 이커머스 주문 정보들, 고객 정보들, 채팅 메시지 등 다양한 정보들을 카프카, 이메일, HTTP 엔드포인트등 다양한 곳으로 전송 된다.
로그 스태시의 세가지 단계
로그스태시의 파이프라인은 3가지의 단계를 거쳐서 활용된다. 바로 입력, 필터, 출력의 단계로 동작하게 되고 각각의 단계에서는 다양한 플러그인을 활용하여 사용할 수 있다.
입력단계
입력 단계는 로그스태시가 데이터를 전달받는 단계이다. 여기서 사용되는 입력 플러그인은 파일에서 입력받을 수도 있고 http 엔드포인트에서 이벤트를 입력받거나 데이터베이스, 카프카 큐 등 다양한 환경에서 입력받을 수 있다.
필터단계
필터 단계는 입력 단계에서 전달받은 이벤트를 XML이나 JSON, CSV 형식으로 파싱할 수 있다. 여기서 플러그인을 활용해 지리적 위치를 확인하거나 데이터베이스에서 데이터를 조회하는 등의 보강작업을 하고 있습니다.
출력단계
출력단계는 이벤트를 보내는 역활을 담당한다. 일반적으로 활용되는 것은 엘라스틱 서치에 저장하는 방식으로 많이 활용하지만 이외에도 카프카 큐나 데이터베이스, 파일등 다양한 형태로 이벤트를 보낼 수 있다.
로그 스태시의 활용 사례
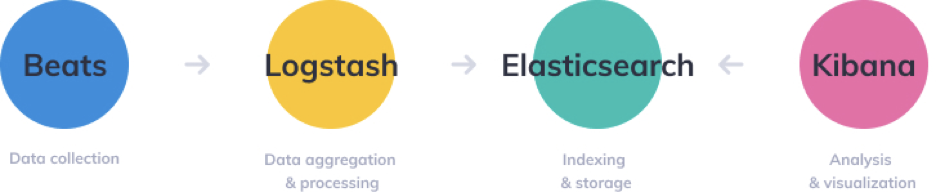
가장 일반적으로 활용되는 형태로 위의 그림과 같은 아키텍처를 구성한다. 비츠에서 데이터를 전달하고 로그스태시에 전달한 다음 데이터 전처리 과정을 거치거 엘라스틱 서치에 전달한다. 전달된 데이터는 키바나를 통해 시각화된 형태로 볼 수 있게 된다. 여기서 비츠를 생략해도 되지만 로그스태시보다 더 가볍게 운영할 수 있고 로그나 메트릭 정보와 같이 지속적으로 전달해야되는 이벤트를 처리하는데 특화되어 있어 로그 스태시만 활용하는 것보다 더 안정적이고 효율적으로 처리할 수 있다.
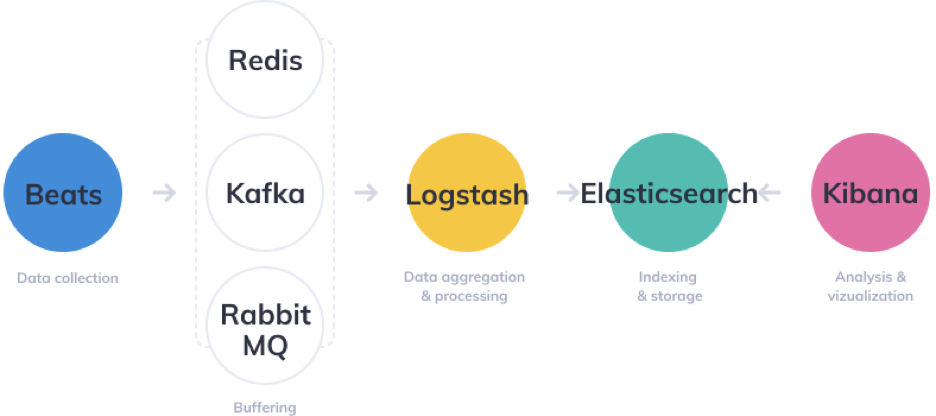
더 큰 크기의 대용량 데이터를 지속적으로 처리해야 된다고 한다면 위와같은 아키텍처로 구성하여 많이 활용한다. 위와 같은 구조는 여러개의 로그스태시 서버와 엘라스틱 서치 서버를 두고 분산처리해야 될 때 자주 활용되는 아키텍처이다. 중간에 레디스, 카프카, RabbitMQ와 같이 버퍼(메시징 큐)를 담당하여 분산적으로 데이터를 처리하면서 대용량 데이터를 다루는 데 좀 더 안정적으로 운영할 수 있다.
로그 스태시의 확장성
로그 스태시는 지원해주는 기능이 많은 만큼 소규모의 데이터 파이프 라인에는 적합하지 않은 선택이다. 만약 기본적인 로그나 매트릭 정보들을 전달하는 경우 FileBeats를 활용하여 아래와 같은 디자인으로 구축해도 충분히 좋은 선택이다.

로그 스태시를 활용하기 좋은 상황
- 갑작스러운 데이터 입력량의 증가나 부하가 발생할 수 있는 시스템: 로그스태시는 갑작스러운 데이터 입력이 들어와서 백프레셔가 발생했을 때 Adaptive Disk-Based Buffering System을 통해 입력량에 따라 버퍼의 크기를 조절하고 디스크에 데이터를 임시적으로 저장하면서 서버가 다운되더라도 안정적으로 운영할 수 있도록 설계가 되어 있다.
- 다양한 환경에서 데이터를 수집해야할 때: 로그스태시는 다양한 플러그인을 제공하여 S3, 데이터베이스, 메시지큐, HDFS등 과 같은 환경에서 데이터를 입력받을 수 있다.
- 다양한 환경에서 데이터를 전달해야할 때: 위에서 설명했듯이 수집뿐만 아니라 전달하는데에도 다양한 플랫폼 환경에서 데이터를 전달 할 수 있다.
- 정교한 데이터 전처리가 필요할 때: 로그 스태시는 데이터를 전처리하는 데에도 도움을 주는 플러그인이 다수 존재하고 있다. 그래서 고품질의 데이터를 만들어야 하는 파이프라인을 만들어야 한다면 로그스태시를 통해 처리하는 것을 추천한다.
- 고가용성의 데이터 파이프라인을 구축해야할 때: 로그 스태시는 클러스터링, 로드밸런싱, 최소 한번의 전송 등을 보장하기 때문에 고가용성의 데이터 파이프라인을 구축해야할 때 좋은 선택이 될 수 있다.
로그스태시를 활용한 인프라 구축

분산된 엣지 호스트 서버에서 로그스태시 서버에 집중적으로 데이터를 보내고 로그스태시 서버는 전달받은 데이터들을 분산된 노드에 로드밸런싱하면서 데이터 수집 처리를 분산시킨다. 그리고 logstash는 persistent queues를 통해 디스크에 데이터를 임시적으로 저장하여 노드의 장애가 발생하더라도 데이터 손실을 막을 수 있다. 엘라스틱 서치에 보낼 때에는 동기적으로 처리하고 Acknowledgement를 지원하기 때문에 최소 한번 전달이 보장된다.
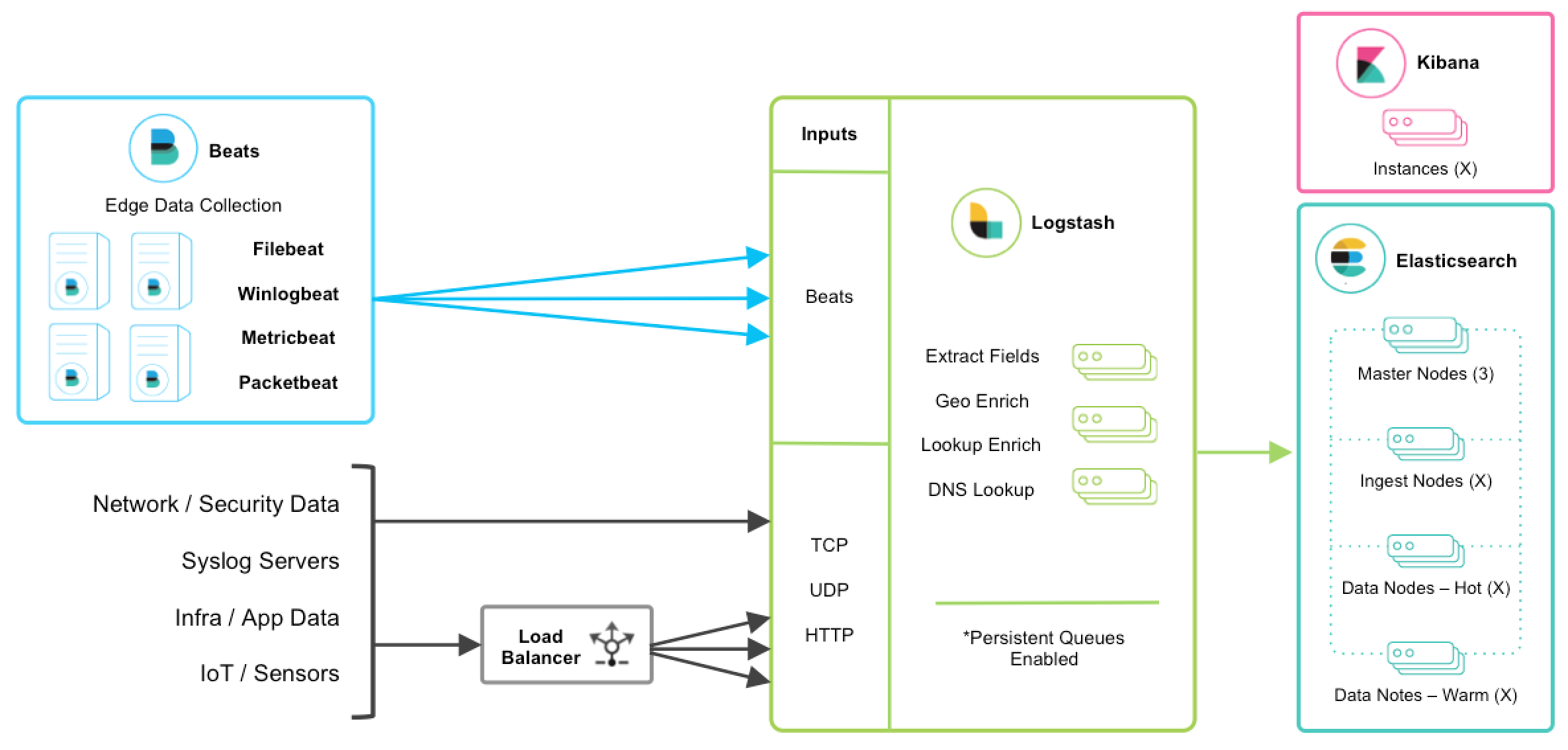

로그스태시는 엘라스틱 서치와 마찬가지로 이론상 무한정의 스케일 아웃이 가능하기 때문에 뒷받침해주는 인프라가 있다면 대규모 트래픽에도 안정적으로 데이터를 수집할 수 있다. 하지만 이러한 인프라는 기술에 대한 높은 이해도를 요구하고 높은 비용의 서버 환경을 요구하기 때문에 충분히 이해하지 않은 상태로 활용하게 되면 배보다 배꼽이 더 커질 수 있다.
예시로 로그스태시는 하나의 노드에 JVM 힙 크기는 4GB 이상 8GB 이하을 권장하고 있다. 그리고 절대 OS의 50%~75%이상의 힙크기를 지정하지 말라고 하고 있다. 만약 JVM의 힙크기를 이상으로 설정했다면 OOM이슈가 발생할 것이고 적게 설정했다면 CPU 사용이 급격하게 증가하여 불필요한 가비지 수집을 하게 될 것이다. 그러니 공식문서를 잘 읽어보고 해당 기술에 대해 잘 이해한 뒤에 실무에 사용하는 것이 좋을 것이다.
'Elasticsearch' 카테고리의 다른 글
| ELK 정복하기 - 애널라이저(분석기) (0) | 2023.08.20 |
|---|---|
| Elasticsearch7 이상부터 사용해야하는 이유 (0) | 2023.07.17 |
| Elastic search 설치(Mac, Docker) (0) | 2023.07.15 |
| ES1 IndexCreationException 트러블 슈팅 (0) | 2023.07.04 |
| Elastic Search 시작하기 이론편 (0) | 2023.06.18 |
로그 스태시란?
로그 스태시는 지어진 이름 처럼 과거에는 어플리케이션들에서 발생하는 로그들을 엘라스틱서치에 전달하는 역활만을 해왔다. 이는 가장 많이 활용해왔던 수단 중 하나였지만 점점 발점해오면서 데이터 전달하고 필터링 하는 역활도 할 수 있게 되었고 나중에는 인기 있는 데이터 파이프 라인 툴 중 하나로 자리잡게 되었다.
로그스태시는 다양한 이벤트들을 전달받아 핸들링할 수 있다. 이러한 이점은 다양한 형태의 데이터 처리 할 수 있다는 의미이기도 하다. 예를 들어 로그 파일, 이커머스 주문 정보들, 고객 정보들, 채팅 메시지 등 다양한 정보들을 카프카, 이메일, HTTP 엔드포인트등 다양한 곳으로 전송 된다.
로그 스태시의 세가지 단계
로그스태시의 파이프라인은 3가지의 단계를 거쳐서 활용된다. 바로 입력, 필터, 출력의 단계로 동작하게 되고 각각의 단계에서는 다양한 플러그인을 활용하여 사용할 수 있다.
입력단계
입력 단계는 로그스태시가 데이터를 전달받는 단계이다. 여기서 사용되는 입력 플러그인은 파일에서 입력받을 수도 있고 http 엔드포인트에서 이벤트를 입력받거나 데이터베이스, 카프카 큐 등 다양한 환경에서 입력받을 수 있다.
필터단계
필터 단계는 입력 단계에서 전달받은 이벤트를 XML이나 JSON, CSV 형식으로 파싱할 수 있다. 여기서 플러그인을 활용해 지리적 위치를 확인하거나 데이터베이스에서 데이터를 조회하는 등의 보강작업을 하고 있습니다.
출력단계
출력단계는 이벤트를 보내는 역활을 담당한다. 일반적으로 활용되는 것은 엘라스틱 서치에 저장하는 방식으로 많이 활용하지만 이외에도 카프카 큐나 데이터베이스, 파일등 다양한 형태로 이벤트를 보낼 수 있다.
로그 스태시의 활용 사례
가장 일반적으로 활용되는 형태로 위의 그림과 같은 아키텍처를 구성한다. 비츠에서 데이터를 전달하고 로그스태시에 전달한 다음 데이터 전처리 과정을 거치거 엘라스틱 서치에 전달한다. 전달된 데이터는 키바나를 통해 시각화된 형태로 볼 수 있게 된다. 여기서 비츠를 생략해도 되지만 로그스태시보다 더 가볍게 운영할 수 있고 로그나 메트릭 정보와 같이 지속적으로 전달해야되는 이벤트를 처리하는데 특화되어 있어 로그 스태시만 활용하는 것보다 더 안정적이고 효율적으로 처리할 수 있다.
더 큰 크기의 대용량 데이터를 지속적으로 처리해야 된다고 한다면 위와같은 아키텍처로 구성하여 많이 활용한다. 위와 같은 구조는 여러개의 로그스태시 서버와 엘라스틱 서치 서버를 두고 분산처리해야 될 때 자주 활용되는 아키텍처이다. 중간에 레디스, 카프카, RabbitMQ와 같이 버퍼(메시징 큐)를 담당하여 분산적으로 데이터를 처리하면서 대용량 데이터를 다루는 데 좀 더 안정적으로 운영할 수 있다.
로그 스태시의 확장성
로그 스태시는 지원해주는 기능이 많은 만큼 소규모의 데이터 파이프 라인에는 적합하지 않은 선택이다. 만약 기본적인 로그나 매트릭 정보들을 전달하는 경우 FileBeats를 활용하여 아래와 같은 디자인으로 구축해도 충분히 좋은 선택이다.
로그 스태시를 활용하기 좋은 상황
- 갑작스러운 데이터 입력량의 증가나 부하가 발생할 수 있는 시스템: 로그스태시는 갑작스러운 데이터 입력이 들어와서 백프레셔가 발생했을 때 Adaptive Disk-Based Buffering System을 통해 입력량에 따라 버퍼의 크기를 조절하고 디스크에 데이터를 임시적으로 저장하면서 서버가 다운되더라도 안정적으로 운영할 수 있도록 설계가 되어 있다.
- 다양한 환경에서 데이터를 수집해야할 때: 로그스태시는 다양한 플러그인을 제공하여 S3, 데이터베이스, 메시지큐, HDFS등 과 같은 환경에서 데이터를 입력받을 수 있다.
- 다양한 환경에서 데이터를 전달해야할 때: 위에서 설명했듯이 수집뿐만 아니라 전달하는데에도 다양한 플랫폼 환경에서 데이터를 전달 할 수 있다.
- 정교한 데이터 전처리가 필요할 때: 로그 스태시는 데이터를 전처리하는 데에도 도움을 주는 플러그인이 다수 존재하고 있다. 그래서 고품질의 데이터를 만들어야 하는 파이프라인을 만들어야 한다면 로그스태시를 통해 처리하는 것을 추천한다.
- 고가용성의 데이터 파이프라인을 구축해야할 때: 로그 스태시는 클러스터링, 로드밸런싱, 최소 한번의 전송 등을 보장하기 때문에 고가용성의 데이터 파이프라인을 구축해야할 때 좋은 선택이 될 수 있다.
로그스태시를 활용한 인프라 구축
분산된 엣지 호스트 서버에서 로그스태시 서버에 집중적으로 데이터를 보내고 로그스태시 서버는 전달받은 데이터들을 분산된 노드에 로드밸런싱하면서 데이터 수집 처리를 분산시킨다. 그리고 logstash는 persistent queues를 통해 디스크에 데이터를 임시적으로 저장하여 노드의 장애가 발생하더라도 데이터 손실을 막을 수 있다. 엘라스틱 서치에 보낼 때에는 동기적으로 처리하고 Acknowledgement를 지원하기 때문에 최소 한번 전달이 보장된다.
로그스태시는 엘라스틱 서치와 마찬가지로 이론상 무한정의 스케일 아웃이 가능하기 때문에 뒷받침해주는 인프라가 있다면 대규모 트래픽에도 안정적으로 데이터를 수집할 수 있다. 하지만 이러한 인프라는 기술에 대한 높은 이해도를 요구하고 높은 비용의 서버 환경을 요구하기 때문에 충분히 이해하지 않은 상태로 활용하게 되면 배보다 배꼽이 더 커질 수 있다.
예시로 로그스태시는 하나의 노드에 JVM 힙 크기는 4GB 이상 8GB 이하을 권장하고 있다. 그리고 절대 OS의 50%~75%이상의 힙크기를 지정하지 말라고 하고 있다. 만약 JVM의 힙크기를 이상으로 설정했다면 OOM이슈가 발생할 것이고 적게 설정했다면 CPU 사용이 급격하게 증가하여 불필요한 가비지 수집을 하게 될 것이다. 그러니 공식문서를 잘 읽어보고 해당 기술에 대해 잘 이해한 뒤에 실무에 사용하는 것이 좋을 것이다.
'Elasticsearch' 카테고리의 다른 글
| ELK 정복하기 - 애널라이저(분석기) (0) | 2023.08.20 |
|---|---|
| Elasticsearch7 이상부터 사용해야하는 이유 (0) | 2023.07.17 |
| Elastic search 설치(Mac, Docker) (0) | 2023.07.15 |
| ES1 IndexCreationException 트러블 슈팅 (0) | 2023.07.04 |
| Elastic Search 시작하기 이론편 (0) | 2023.06.18 |