

어느날 아침에 출근하고 보니 앱이 계속 느려졌다는 문의가 들어오고 있었다. 이에 놀란 나는 헐레벌떡 에러로그 모니터링 시스템을 확인해봤고 낯선 에러 로그가 쌓여 있는 것을 확인할 수 있었다. 에러 로그에 있는 Trace 정보들을 통해 확인해보니 API 서버의 디비 커넥션 풀이 계속 끊기는 것을 확인할 수 있었고 좀 더 자세히 살펴보기위해 보기 위해 로드밸런서의 헬스체크를 확인해보니 한쪽 서버의 헬스 체크가 죽어 있었다...
피토하며 돌아가는 서버
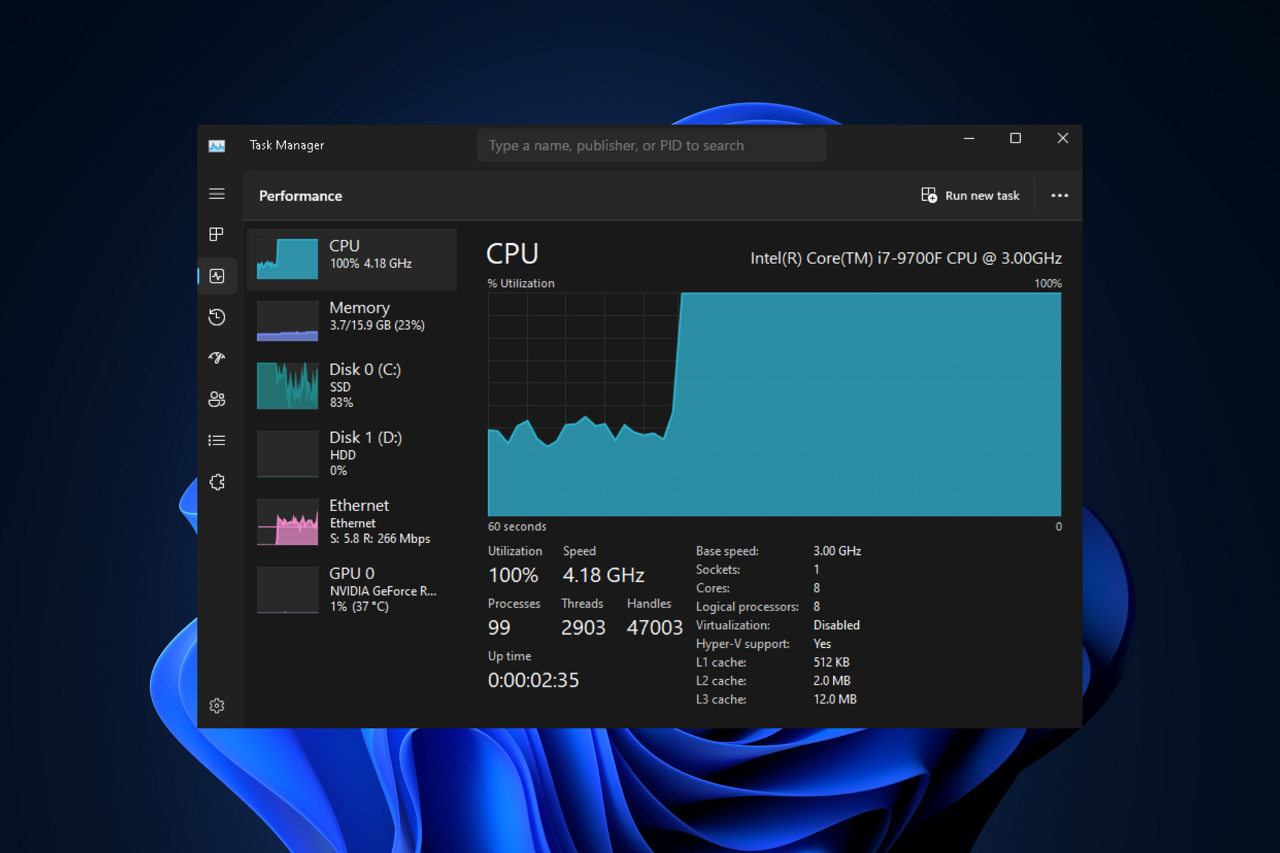
헬스 체크가 죽어 있는 서버의 인스턴스는 위의 그림처럼 100%의 가까이 되는 CPU 사용률을 보이며 돌아가고 있었기에 빨리 연결을 끊고 원인을 파악해야 했다. 그래서 ssh 접속을 시도했지만 서버 과부하로 인해 내부에 접근할 수 없었고 그래서 어쩔 수 없이 인스턴스를 재부팅하여 다시 서버를 올리는 방법으로 정상화를 시켰다. 장애 원인을 찾기 위해 서버 메트릭 정보들과 로그들을 살펴면서 아래와 같은 특이상황을 발견할 수 있었다.
- CPU의 사용률이 30~40%를 유지하다가 짧은 시간내에 갑작스럽게 치솟아 오름.
- 네트워크 I/O가 평소에 비해 많이 발생했지만 CPU의 사용량 만큼 크게 증가하지 않음.
- 로그 적재량을 확인해본 결과 평소보다 조금 더 많이 쌓였지만 과부화를 줄 정도로 요청 로그가 쌓이지는 않음.
- 열려있는 다른 포트를 통해 디도스 공격을 가하지 않았는지 확인하기위해 포트 접속 로그들을 확인해봤지만 서버가 죽을만큼의 트래픽 공격은 들어오지 않음.
위와 같은 특이 상황들을 살펴보고 의논해본 결과 문제가 발생할 수 있는 가설들을 리스트업 했다. 지금 당장 리스트업한 가설들을 모두 증명하기에는 많은 리소스를 들여야했고 단순히 일시적인 장애일 수도 있기 때문에 경보 알림 시스템을 추가로 구축하여 CPU 사용률이 80% 이상 발생한다면 알림을 보내도록 구축한 후 모니터링하면서 상황을 지켜보기로 했다.
우리가 세웠던 가설들
- 디도스 공격(희박함)
- 클라우드 서버의 하드웨어 이슈(CPU 출력량을 확인해봤지만 가능성이 희박했음)
- 올라간 웹서버의 잘못된 설정으로 인한 과부화
- 잘못된 어플리케이션 로직으로 인한 성능저하 발생 후 과부화
- 과도한 트래픽으로 인한 서버 장애
똑같은 장애 발생

아니나 다를까 경보는 주말에 울리기 시작했고 아침부터 골치를 썩였다. 그렇게 살펴보던 중 이전에 장애가 발생한 같은 서버의 인스턴스에 장애가 발생했을 것이라고 생각하고 해당 인스턴스의 메트릭 정보를 확인했었는데 정상적으로 잘 돌아가고 있었다. 그래서 알림이 잘못되었나 살펴보니 다른 서버의 인스턴스에서 CPU 과부화가 발생한 것을 확인할 수 있었다. 우리는 해당 이슈가 단순히 서버의 인스턴스의 일시적인 문제가 아니라 전체 시스템 장애를 불러올 수 있는 이슈라고 판단했고 각자 주말에 래퍼런스 조사를 한 후 평일에 본격적으로 어떻게 대응할지 논의해보기로 했다.
클라우드 인프라 지식의 부재

일단 이전에 세웠던 가설을 증명하기 위해서는 자세한 메트릭 정보들이 필요했었고 아마존 클라우드에 대해 능숙한 사람이 요구되었지만 현재의 우리의 상황에서는 인프라를 전문적으로 다룰 수 있는 인력이 없었다. 그렇게 우리는 CloudWatch에서 제공해주는 단편적인 메트릭을 통해 추측해야 되는 상황이였다. 그렇게 우리는 어떻게 해결해야하나 고민을 하던 중 이전에 AWS를 관리하기 위해 제휴를 맺은 기업이 있다고 이야기가 나왔고 그렇게 우리는 제휴기업을 통해 기술지원을 받을 수 있었다. 이슈를 전달하기 위해 문제가 발생한 시간과 메트릭 정보가 담겨 있는 스크린샷, 가설들을 전부 정리해서 문의를 넣었고 덕분에 빠른 시간내에 답변을 받을 수 있었다.
Burstable performance instances
답변을 확인해보니 문제 원인은 허무하게도 문제의 원인은 우리가 현재 사용하고 있는 EC2 서버의 인스턴스 유형 때문이였다.
좀 더 자세하게 설명하자면 현재 사용하고 있는 서버의 인스턴스의 타입이 기본 CPU 사용량을 초과(CPU 버스트)하게 되면 크레딧을 소모하게 되고 해당 크레딧을 전부 소모하게 되면 서버 인스턴스의 성능에 제약을 걸어버리게 되어 서버에 과부화가 발생하게 되었다. 그 개념을 좀 더 자세하게 설명하자면 아래와 같다.
버스트와 크레딧
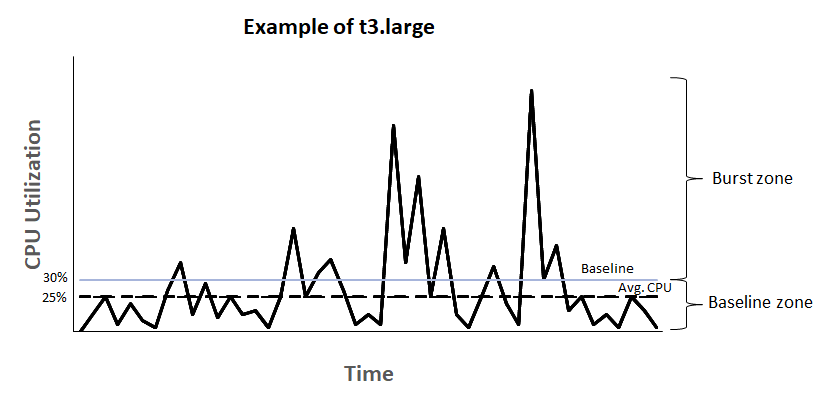
위의 그림처럼 서버를 운영하다보면 일정 시간에 CPU의 사용율이 튀는 상황(CPU 버스트)이 발생할 수 있다. 여기서 문제는 저 사용율이 튀는 버스트 존만큼 CPU 사양을 설정하게 되면 서버 비용이 많이 발생하게 되고 그렇다고 평균 CPU 사용율에 맞게 조정하자니 갑자기 높게 올라가버리는 CPU 사용율로 인해 서버가 견디지 못하고 죽어버리는 일이 발생할 수 있다. AWS는 이러한 문제를 해결하기 위해 버스트 가능 인스턴스의 개념을 도입하게 되었다.

사우나에 가다보면 위의 그림과 같은 밴드를 받고 사용해본 경험이 있을 것이다. 사우니를 사용할 때 목욕탕과 사우나는 기본적으로 사용이 가능하지만 때밀이, 안마, 헬스장 등과 같은 추가적인 시설을 사용하려면 밴드를 찍고 비용을 지불해아하는 것처럼 EC2의 버스트 가능 인스턴스도 기본 cpu 사용율을 유지하는 것은 크레딧을 소모하지 않지만 기본 cpu 사용율 이상의 추가적인 cpu 사용이 발생하게 된다면 크레딧을 소모하는 형태로 구현이 되어 있다. 참고로 크레딧은 각 서버 인스턴스 마다 누적량이 다르고 적립량도 다르다.
서버 인스턴스 유형별 크레딧
| 인스턴스 유형 | 시간당 누적되는 크레딧 | 누적 가능한 최대 크레딧 | vCPU | vCPU당 기준 사용률 |
| T2 | ||||
| t2.nano | 3 | 72 | 1 | 5% |
| t2.micro | 6 | 144 | 1 | 10% |
| t2.small | 12 | 288 | 1 | 20% |
| t2.medium | 24 | 576 | 2 | 20%** |
| t2.large | 36 | 864 | 2 | 30%** |
| t2.xlarge | 54 | 1296 | 4 | 22.5%** |
| t2.2xlarge | 81.6 | 1958.4 | 8 | 17%** |
| T3 | ||||
| t3.nano | 6 | 144 | 2 | 5%** |
| t3.micro | 12 | 288 | 2 | 10%** |
| t3.small | 24 | 576 | 2 | 20%** |
예시로 현재 t3.small 타입의 인스턴스를 사용하게되면 AWS에서 시간당 24크레딧을 발급해준다. 그렇게 계속 누적되다가 일정 시간에 20%가 넘는 CPU 사용율이 발생할 경우 20% 넘었던 구간의 시간(ms)을 기준으로 크레딧을 일정량 소모하게 된다. 그리고 발급되고 있는 크레딧을 계속 누적되는 것이 아니라 특정 양만큼만 누적이 되고 더이상 누적이 안되기 때문에 크레딧 사용을 주의해야한다. 예시로 t3.small은 576의 크레딧만 누적할 수 있다. 그 이상 발급이 된 크레딧은 버려지게 된다.
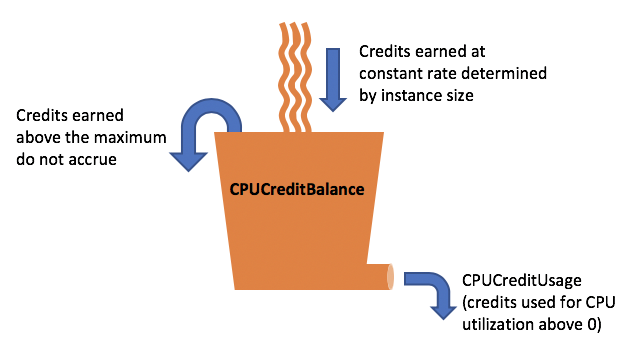
이러한 구조를 통해 버스트 가능 인스턴스를 활용하게 되면 효율적인 서버 활용이 가능하다. 하지만 여기서 문제가 발생할 수 있는 부분은 공급보다 수요가 많아서 크레딧을 전부 소모하게 된다면 성능적으로 제약을 걸어버려서 서버에 장애를 일으킬 수 있다는 점이다. 이러한 부분을 인지하지 못하고 사용하고 있었던 나는 그대로 원인모르는 서버 장애를 맞게 된 것이다.
문제 해결을 위한 방법들

계속 문제를 가져가기에는 서비스 장애를 발생시킬 수 있는 이슈이기 때문에 당장 해결해야 했었다. 그래서 우리는 다양한 문제 해결 방법들을 제시하면서 이야기를 나눴고 아래와 같이 정리가 되었다.
- 비지니스 로직의 성능 최적화를 통한 어플리케이션 서버 개선
- 고가용성의 인프라를 구축을 통한 유연하게 활용할 수 있는 서버 환경 구축
- 자동화된 장애복구 시스템을 통해 장애 발생시 서버 자동 복구
여러 이야기를 나누고 회의를 통해 결국 2번을 선택하게 되었다. 이유를 설명하자먀면 다음과 같다.
1번을 진행하려면 모든 API Request에 지연시간, 메모리 사용률등과 같은 메트릭 정보를 모니터링하는 시스템이 필요하고 하나의 API만 개선한다고 드라마틱하게 개선되지 않기 때문에 많은 부분의 비지니스 로직을 개선해야했고 우리가 생각했던 것보다 많은 공수가 발생할 것이라고 판단하였다. 그런 이유로 인해 우리는 1번은 보류하게 되었다.
3번은 가장 공수가 적게 드는 일이지만 근본적으로 문제를 해결할 수 없다고 결론이 나왔다. 왜냐하면 장애가 서버의 인스턴스의 연결을 끊고 복구하고 있는동안 현재 연결된 인스턴스도 과부화 상태가 되어버리면 결국 두개의 서버다 연결을 끊어버리는 장애가 발생할 수 있기 때문이다. 이 문제를 해결하기 위해 하나의 서버를 복구하는 동안 현재 서버는 연결을 지속시킬 수 있지만 결국 서버의 성능 저하로 인해 유저들이 사용하는 서비스는 현저히 느려질 것이기 때문에 보류하게 되었따.
2번은 어느정도 공수는 들지만 선택했던 이유가 두가지가 있는데 첫번째는 우리 서비스 도메인의 특성과 매우 부합했기 때문이다. 현재 서비스의 도메인은 유저들이 특정 기간과 시간에만 주로 활용했었고 그 기간외에는 트래픽이 갑자기 줄어들었다가 나중에 다시 오르는 특성을 가 졌었기 때문에 트래픽에 맞춰 인프라 다운 스케일할 수 있는 고가용성의 인프라를 구축하는 것이 유리했다. 두번째는 인프라 이전이였다. 현재 다양한 서비스가 하나의 클라우드 계정으로 관리되면서 비용 추적하기도 어려웠고 AWS의 VPC, 네트워크망, 보안 그룹등이 혼재되어 사용되면서 나중에 관리할 때 다른 서비스에 장에가 발생할 수 있어서 인프라 인전을 계획하고 있었지만 명분이 없어 진행하지 못하고 있었다.
후기
이번 이슈는 내가 이직을 하기로 확정을 한 후에 발생하여 해당 이슈를 완전하게는 해결하지 못하고 인수인계하고 가는 것으로 마무리 되었지만 장애 원인을 추적하는 과정에서 AWS에서 제공했었지만 알지못했던 기능들과 새로 배웠던 개념들에 대해 많이 알 수 있었고 문제 원인과 해결 방법에 대해 명확히 정리가 되서 만족할 수 있었던 장애 대응이였다. 이직이 확정한 이후로 발생해서 다음 개발자 분에게 책임을 떠넘기는 상황이 된 것 같아서 찜찜하지만... 그래도 다음 개발자분이 내가 그 남은 기간동안 할 수 있었던 최선을 다했다는 것을 알아주셔서 감사 하다고 이야기를 드리고 마무리 지을 수 있었다.
참고
버스트 가능 성능 인스턴스에 대한 주요 개념 및 정의 - Amazon Elastic Compute Cloud
버스트 가능 성능 인스턴스에 대한 주요 개념 및 정의 기존 Amazon EC2 인스턴스 유형은 고정된 CPU 리소스를 제공하는 반면, 성능 순간 확장 가능 인스턴스는 기본 수준의 CPU 사용률을 제공하면서
docs.aws.amazon.com
https://docs.aws.amazon.com/ko_kr/AWSEC2/latest/UserGuide/burstable-performance-instances.html