
트래픽이 별로 없는 서비스에서는 동시성 문제를 마주칠 일이 거의 없다. 그래서 몇 년을 개발하면서 한 번도 안 터뜨려본 사람도 많다. 나도 동시성 이슈를 해결한 경험이 많지는 않다. 하지만 트래픽이 적다고 안 터지는 건 아니다. 클라이언트의 더블 클릭, 네트워크 재시도, 비동기로 동작하는 컴포넌트. 이런 것만으로도 같은 요청이 거의 동시에 도착한다. 그 순간 데이터 정합성은 깨진다.
그래서 결국 알아야 한다. 언젠가는 마주칠 문제이고 이런 설계 미스로 인해 서비스 신뢰도와 매출의 하락이 발생할 수 있기 때문이다.
이 글에서는 가장 흔한 동시성 문제인 갱신 분실(lost update)을 재고 차감 시나리오로 재현하고, 이걸 막는 다섯 가지 방법을 비교해보려고 한다. Redis 분산락, DB 격리수준 + Unique Constraint, 메시지 큐 직렬화, PostgreSQL Advisory Lock, 낙관적 락. 다 알고 있다고 생각했는데, 막상 "어떤 걸 쓸까" 고르려니 잘 대답하기 어려웠다. 정리가 필요했다.
비관적락을 통한 동시성 제어
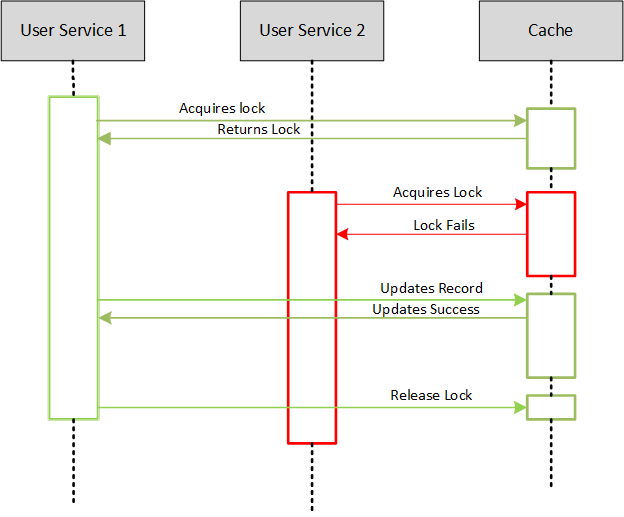
단일 데이터베이스 환경이라면 비관적 락이 가장 많이 쓰인다. 구현이 쉽고 롤백도 깔끔해서 많은 개발자가 우선 선택하는 방법이다.
가장 큰 단점은 성능이다. 한 트랜잭션이 레코드를 잡고 있으면 다른 트랜잭션은 무조건 기다려야 한다. 대기하는 동안 요청이 계속 쌓이면 병목이 생기고, 심하면 시스템 장애로까지 이어진다.
트래픽이 적을 때는 보이지 않는다. 하지만 동시 요청이 한 지점에 몰리는 순간, 가장 먼저 무너지는 게 비관적 락이다.
비관적 락을 쓸 때 한 가지 주의할 게 있다. 여러 레코드에 락을 걸 때는 항상 같은 순서로 걸어야 한다.
트랜잭션 A가 레코드 1을 잡고 레코드 2를 기다리는데, 트랜잭션 B가 반대로 레코드 2를 잡고 레코드 1을 기다리면 어떻게 될까. 서로가 서로의 락을 기다리면서 영원히 안 풀린다. 데드락이다. 그래서 다중 레코드에 락을 걸 일이 있다면, ID 기준이든 뭐든 정렬 기준을 정해두고 모든 트랜잭션이 같은 순서로 접근하도록 만들어야 한다.
낙관적 락을 통한 제어
그 다음으로 많이 쓰는 게 낙관적 락이다.
동작 방식은 단순하다. 테이블에 version이라는 컬럼을 두고, 업데이트할 때마다 +1 한다. 그리고 업데이트 시점에 "내가 읽었을 때의 버전"과 "지금 DB의 버전"이 같은지 확인한다. 다르면 누군가 먼저 수정했다는 뜻이니까 에러를 던지고 롤백한다.
락을 안 걸기 때문에 비관적 락처럼 다른 트랜잭션을 막지 않는다. 그래서 처리량이 좋다. 하지만 충돌이 자주 일어나는 환경이면 얘기가 달라진다. 매번 재시도해야 하니까 오히려 비관적 락보다 느려질 수 있다.
결국 낙관적 락은 "충돌이 거의 없을 거다"라는 전제 위에서 동작하는 방법이다. 이름 그대로 낙관적인 셈이다.
Postgres Advisory Lock
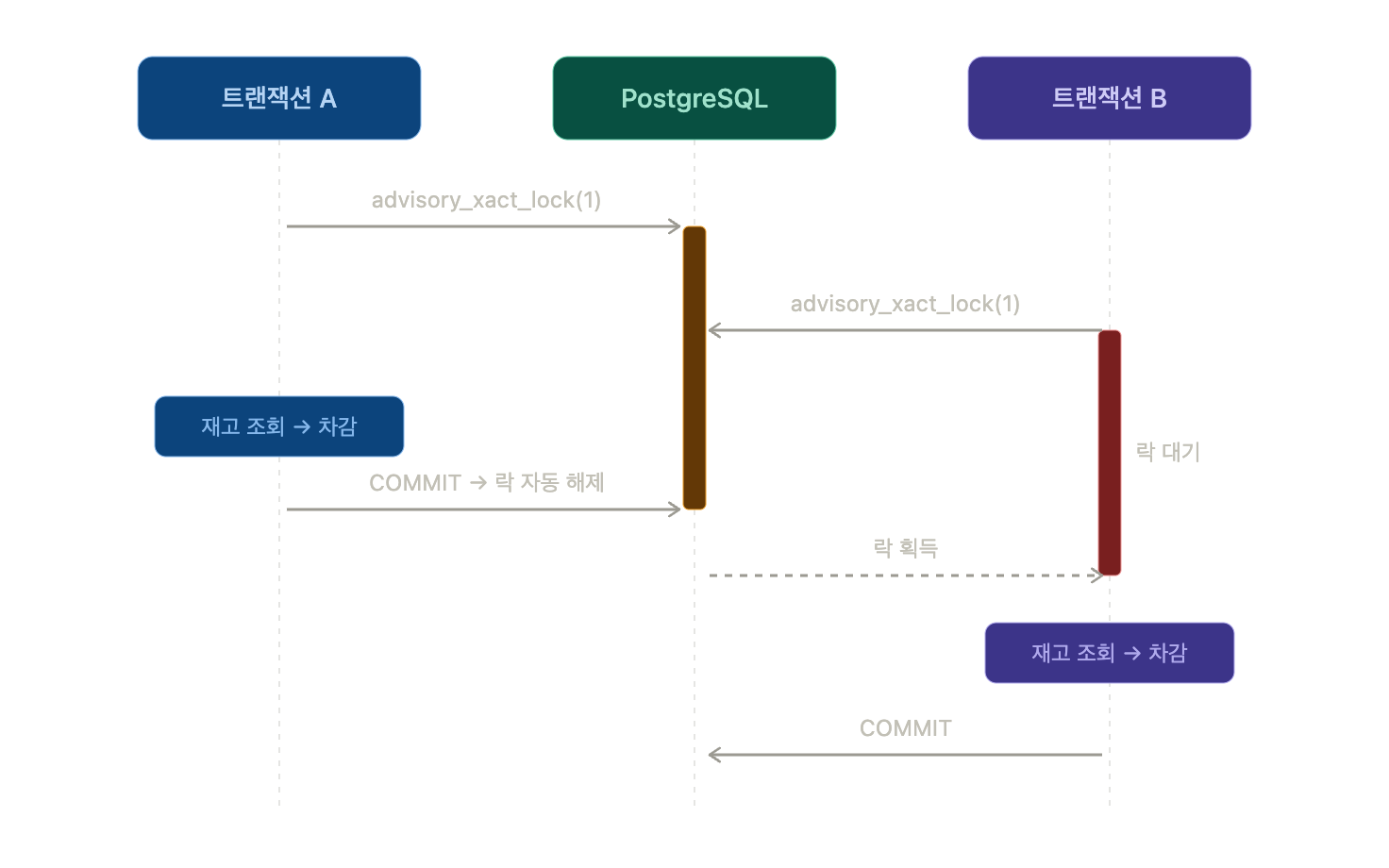
분산 환경에서 락을 DB 바깥으로 빼는 방법으로 Redis를 많이 떠올린다. 하지만 PostgreSQL을 쓰고 있다면 굳이 Redis를 붙이지 않아도 된다. PostgreSQL이 자체적으로 분산락 비슷한 걸 제공하기 때문이다. 바로 Advisory Lock이다.
비관적 락은 실제 레코드를 잠근다. 반면 Advisory Lock은 레코드가 아니라 내가 정한 숫자(키)에 락을 건다. "상품 ID 1번 재고 작업"이라는 논리적인 개념에 락을 거는 셈이다. 그래서 잠글 행이 아직 없어도, 여러 테이블에 걸친 작업이어도 상관없다.
-- 트랜잭션 단위 락, COMMIT 시 자동 해제
SELECT pg_advisory_xact_lock(1); -- 상품 ID 1을 키로 사용
-- 재고 차감 로직...
-- COMMIT 하면 알아서 풀린다락의 종류는 두 가지다. 세션 단위(pg_advisory_lock)는 직접 unlock을 호출하거나 세션이 끊겨야 풀린다.
트랜잭션 단위(pg_advisory_xact_lock)는 트랜잭션이 끝나면 알아서 풀린다. 실무에서는 트랜잭션 단위를 쓰는 게 안전하다. 이유는 잠시 뒤에 나온다.
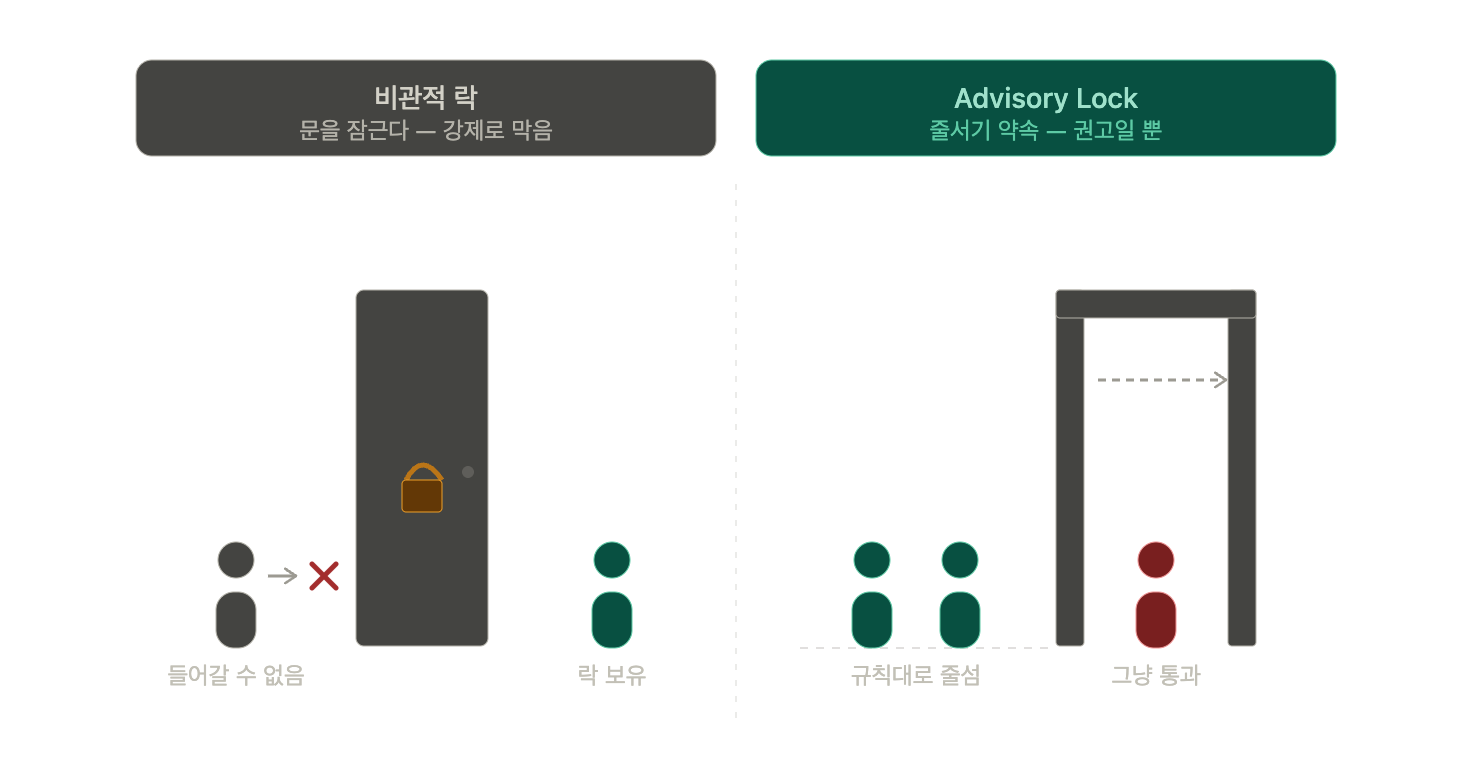
Advisory Lock을 쓸 때 반드시 알아야 할 게 있다. 이름 그대로 "권고적(advisory)" 락이라는 점이다. DB가 실제 데이터를 막아주지 않는다. 누군가 락을 안 걸고 그냥 재고를 수정하면 DB는 그걸 막지 않는다. 모두가 같은 키로 락을 거는 약속을 지켜야만 동작한다.
비관적 락이 한 명이 쓰는 동안 문을 잠가서 다른 사람이 아예 못 들어오게 막는 거라면, advisory lock은 문에 자물쇠가 없고 "다들 같은 규칙으로 줄 서자"는 약속에 가깝다. 약속을 안 지키는 사람이 있으면 그냥 들어가 버린다.
그리고 세션 단위 락은 커넥션 풀과 만나면 골치 아파진다. unlock을 빼먹은 채 커넥션이 풀로 반납되면, 다음에 그 커넥션을 빌려간 요청이 락을 들고 있는 상태가 된다. 앞에서 트랜잭션 단위를 쓰라고 한 게 이 이유다.
마지막으로, 키는 그냥 숫자(bigint)다. 문자열로 잠그고 싶으면 해시해서 숫자로 바꿔야 하는데, 이때 해시 충돌이 생길 수 있다. 서로 다른 두 대상이 같은 키로 매핑되면 엉뚱하게 직렬화된다.
정리하면 Advisory Lock은 "추가 인프라 없이 단일 PostgreSQL 안에서 분산락이 필요할 때" 쓰는 방법이다. Redis를 붙이는 부담은 없지만, 결국 락 부하는 DB가 떠안는다. 그리고 DB를 여러 대로 분산하는 순간 무력화된다. 각 DB가 자기만의 락 공간을 가지기 때문이다. 거기까지 가면 그때는 정말 Redis가 필요해진다.
Redis를 활용한 분산락 제어하기
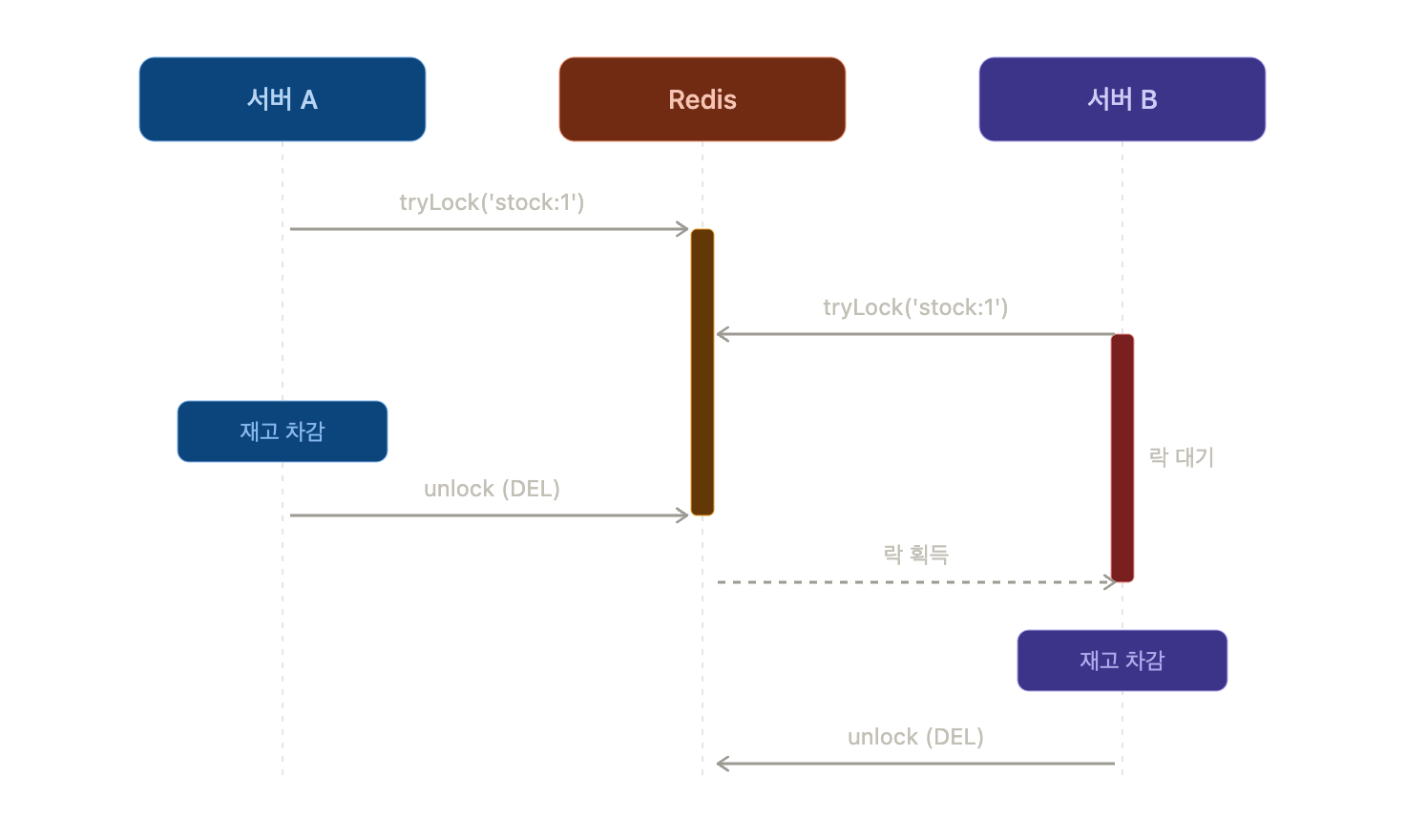
앞에서 본 락들은 전부 DB에 묶여 있었다. 비관적 락도, advisory lock도 결국 "하나의 DB"라는 울타리 안에서만 동작한다. DB를 여러 대로 나누는 순간 그 울타리는 사라진다. 락을 DB 바깥, 모든 서버가 공유하는 한 곳으로 빼야 한다. 그 한 곳으로 가장 많이 쓰이는 게 Redis다.
동작 원리는 단순하다. Redis에 특정 키를 하나 만든다. 락을 잡고 싶은 서버는 그 키를 선점하려 하고, 성공한 서버만 임계 영역에 들어간다. 나머지는 키가 풀릴 때까지 기다린다. 모든 서버가 같은 Redis를 보고 있으니, 서버가 몇 대로 늘어나든 락은 한 곳에서 관리된다.
Spring에서는 보통 Redisson의 RLock을 쓴다. 직접 SETNX로 구현할 수도 있지만, 그러면 만료 처리, 재시도, 락 해제 같은 걸 전부 손으로 짜야 한다. Redisson은 이걸 다 감싸준다.
RLock lock = redissonClient.getLock("stock:" + productId);
try {
// 최대 3초 대기, 점유 후 5초 뒤 자동 해제
boolean acquired = lock.tryLock(3, 5, TimeUnit.SECONDS);
if (!acquired) {
throw new IllegalStateException("락 획득 실패");
}
// 재고 차감 로직...
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}여기서 눈여겨볼 게 두 번째 인자, 만료 시간(lease time)이다. Redis 분산락에는 advisory lock에 없던 문제가 하나 있다. 락을 잡은 서버가 죽어버리면? DB 락은 커넥션이 끊기면 알아서 풀린다. 하지만 Redis는 그 서버가 죽었는지 모른다. 그래서 만료 시간을 걸어둔다. 일정 시간이 지나면 강제로 풀리도록.
그런데 이 만료 시간이 또 다른 함정을 만든다. 작업이 만료 시간보다 오래 걸리면, 아직 일하고 있는데 락이 풀려버린다. 그 틈에 다른 서버가 락을 잡으면 두 서버가 동시에 임계 영역에 들어간다. 막으려던 동시성 문제가 그대로 터지는 것이다. Redisson은 이걸 막으려고 워치독(watchdog)이라는 장치로 락을 자동 연장해주지만, leaseTime을 직접 지정하면 워치독이 동작하지 않는다. 이런 디테일을 모르고 쓰면 오히려 독이 된다.
정리하면 Redis 분산락은 "여러 서버, 여러 DB로 흩어진 환경에서 하나의 공유된 락이 필요할 때" 쓰는 방법이다. 가장 강력하고 가장 범용적이다. 대신 Redis라는 인프라가 하나 더 늘고, 그 Redis가 죽으면 락 전체가 흔들린다. 단일 장애점이 하나 생기는 셈이다. 공짜가 아니다.
큐 직렬화를 통해 동시성 문제 해결하기
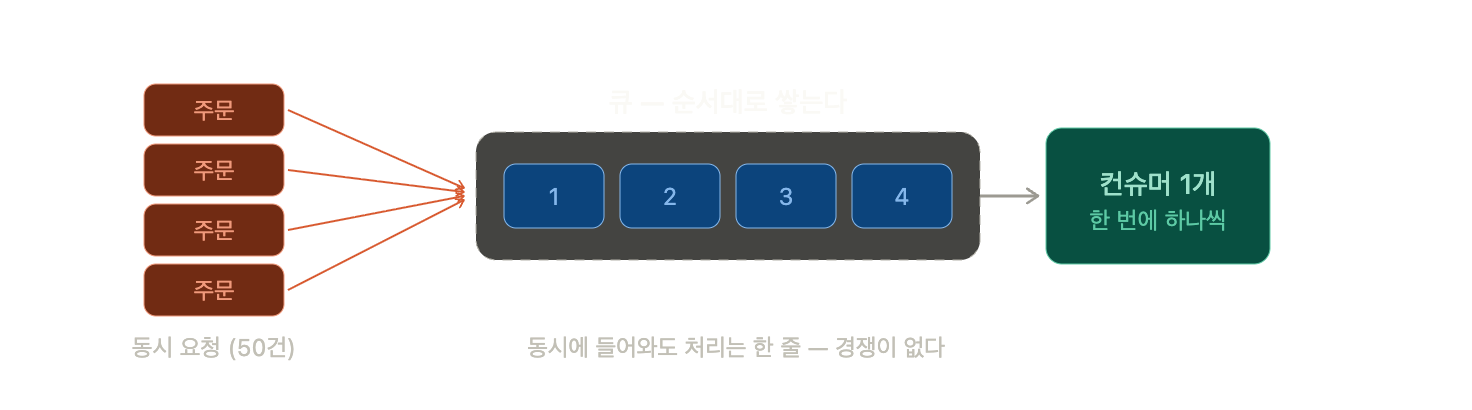
지금까지의 방법은 전부 "동시에 들어오는 걸 어떻게 막을까"였다. 비관적 락도, advisory lock도, Redis 분산락도 결국 줄을 세우는 락이었다. 큐 직렬화는 질문 자체를 바꾼다. 막지 말고, 애초에 동시가 아니게 만들면 되지 않나?
발상은 이렇다. 주문 요청이 들어오면 바로 재고를 차감하지 않는다. 일단 메시지 큐에 넣는다. 그리고 그 큐를 하나의 소비자(consumer)가 순서대로 꺼내서 처리한다. 50명이 동시에 주문해도, 큐에서 꺼내는 건 한 번에 하나다. 동시성 자체가 사라진다. 경쟁할 일이 없으니 락도 필요 없다. RabbitMQ나 Kafka를 많이 쓴다. Kafka라면 같은 상품 ID를 같은 파티션으로 보내는 게 핵심이다. 파티션 하나는 컨슈머 하나가 순서를 보장하며 처리하니까, "상품 1번에 대한 주문"은 항상 한 줄로 직렬화된다.
// 상품 ID를 파티션 키로 → 같은 상품은 같은 파티션 → 순서 보장
kafkaTemplate.send("order-topic", String.valueOf(productId), orderEvent);
락이 없으니 락 때문에 생기던 문제도 없다. 데드락도, 락 대기로 인한 병목도, 만료 시간 같은 고민도 사라진다. 트래픽이 아무리 몰려도 큐가 받아주고, 처리는 뒤에서 차분히 진행된다. 스파이크를 버텨내는 힘이 강하다.
대신 큐 직렬화는 가장 큰 걸 하나 내준다. 즉시성이다.
앞의 락 방식들은 동기적이었다. 주문 요청이 오면 그 자리에서 처리하고 "성공"이나 "재고 부족"을 바로 응답했다. 큐 직렬화는 다르다. 요청은 "접수됐다"까지만 답하고, 실제 재고 차감은 뒤에서 일어난다. 사용자는 자기 주문이 성공했는지 그 순간 알 수 없다. 비동기가 된다는 건 시스템 전체의 설계가 바뀐다는 뜻이다. 결과를 어떻게 다시 알려줄지, 실패하면 어떻게 보상할지, 전부 새로 설계해야 한다. 그리고 처리량의 천장이 생긴다. 순서를 보장하려면 결국 한 줄로 처리해야 하는데, 이건 곧 병렬 처리를 포기한다는 뜻이다. 상품별로 파티션을 나눠 어느 정도 분산할 수는 있어도, "같은 상품"에 대해서는 영원히 한 줄이다.
정리하면 큐 직렬화는 "락으로 막기엔 트래픽이 너무 크고, 비동기를 감당할 수 있을 때" 쓰는 방법이다. 순간적인 폭주를 가장 잘 버티지만, 그 대가로 즉시 응답을 포기하고 시스템을 비동기로 다시 설계해야 한다. 가장 규모가 큰 해법이자, 가장 무거운 해법이다.
정리
모든 쓰기 작업에 동시성 제어를 거는 건 과한 비용이다. 대부분의 요청은 부딪칠 일이 없으니까.
정말 필요한 곳은 따로 있다. 선착순 이벤트, 재고 차감, 좌석 예매처럼 동시 요청이 겹쳤을 때 데이터가 깨지면 손해가 큰 로직. 동시성 제어는 거기에 집중하면 된다.
그리고 방법을 고를 때는 지금의 트래픽과 인프라를 봐야 한다. 단일 DB로 충분한데 Redis를 붙일 필요는 없고, 비동기를 감당 못 하는데 큐를 끌어올 이유도 없다. 처음에 말했듯이 "가장 좋은 방법"은 없다. "지금 우리 시스템에 맞는 방법"이 있을 뿐이다.